Build a semantic search engine with LangChain - Docs by LangChain
一句话总结:语义搜索(Semantic Search)是通过将非结构化文本切分并转化为高维稠密向量,利用向量空间内的几何距离来召回与查询意图高度相关的文档片段的核心技术,它是构建 RAG(检索增强生成)系统的先决条件与数据召回基石。
核心概念与常用 API 解析
在 LangChain 中,构建语义搜索引擎依赖于一条高度标准化的数据摄取与检索流水线,涉及以下核心组件:
- Document(文档对象)
LangChain 中表示文本单元的标准数据结构。包含两个核心属性:page_content(存储实际文本字符串)和metadata(字典,存储来源 URL、页码等元数据,用于后续的过滤与溯源)。 - Document Loaders(文档加载器)
负责从外部源加载数据并实例化 Document 对象。例如 PyPDFLoader 会将 PDF 文件的每一页解析为一个独立的 Document 实例。 - Text Splitters(文本切分器)
大模型的上下文窗口有限,且大段文本的向量特征容易模糊。RecursiveCharacterTextSplitter采用递归策略(按段落、句子、单词逐级尝试),利用chunk_size控制文本块的最大字符数,利用chunk_overlap设置相邻文本块的重叠区域,以防止边界处的语义上下文断裂。 - Embeddings(词嵌入模型)
将文本字符串转换为固定维度的浮点数数组(稠密向量)。在向量空间中,语义相近的文本距离更近。核心方法包括用于批量处理文档的embed_documents和用于处理单条查询的embed_query。 - Vector Stores(向量存储)
专门用于存储文本及其对应向量的数据库对象,支持高效的相似度计算。核心 API 为add_documents(入库)和similarity_search(查询)。 - Retrievers(检索器)
向量存储对象本身不直接实现 LangChain 的 Runnable 协议。通过调用vector_store.as_retriever(),可以将其转化为一个标准检索器。检索器实现了invoke和batch等标准方法,能够无缝接入 LCEL(LangChain 表达式语言)执行链。- 查询方式:
similarity_search:最基础的按相似度查 Top K。similarity_search_with_score:带分数的查询(可用于卡阈值)。as_retriever():这是最重要的方法!它把底层的数据库对象包装成 LangChain 标准的Runnable(可运行组件),从而可以无缝接入到后续的 Agent 或 Chain 链路中。还可以配置search_type="mmr"(最大边际相关性,用于保证搜出来的结果不仅相关,而且尽量多样化,不重复)。
- 查询方式:
周边与扩展 API 梳理
文档中还提及了针对复杂召回场景的周边机制与高级查询 API:
- 异步搜索接口 (asimilarity_search)
针对高并发场景提供的异步版本相似度查询接口,避免 I/O 阻塞。 - 带分数的查询 (similarity_search_with_score)
返回匹配的 Document 以及对应的距离或相似度分数。不同底层向量数据库的打分逻辑可能不同(部分为余弦相似度,部分为 L2 欧式距离),常用于检索后处理和重排(Rerank)。 - 基于向量的查询 (similarity_search_by_vector)
跳过字符串嵌入步骤,直接接受一个已经向量化好的浮点数数组进行查询,适用于多模态检索或级联检索场景。 - 检索策略参数 (search_type** & search_kwargs)**
在调用 as_retriever() 时,可以通过参数定制召回策略:- search_type=“similarity”:默认的相似度检索。
- search_type=“mmr”:最大边际相关性(Maximum Marginal Relevance)。在保证召回内容与问题相关的前提下,惩罚检索结果之间的相似度,从而提升召回结果的多样性,避免输入大模型的上下文信息冗余。
- search_type=“similarity_score_threshold”:通过 search_kwargs={“score_threshold”: 0.8} 设定相似度硬性阈值,直接过滤掉相关性较弱的低质量文档。
- 自定义检索器 (@chain 装饰器)
官方文档展示了如果不使用 as_retriever(),也可以利用 @chain 装饰器将 vector_store.similarity_search 包装为一个自定义的 Runnable 检索器节点。
工程化代码落地示例
在真实的 RAG 生产环境中,基础的文档加载器往往无法处理复杂的财报表格,且每次启动都重新向量化会极大地消耗算力与时间。
以下代码展示了进阶版的语义检索流水线。它引入了三个极其重要的工程实践:
- 多模态结构降维:利用 pdfplumber 将财报中的二维表格降维拍平为 Markdown 格式,防止大模型读取时发生格式错乱。
- 本地硬件加速:使用 BGE-M3 模型并开启苹果 MPS 芯片加速(生产服务器可替换为 CUDA),实现数据绝对隐私与本地极速推理。
- 向量索引缓存:通过 FAISS 的本地落盘机制,实现数据的“一次向量化,无限次秒级热启动”。
PDF 文件下载地址:https://s1.q4cdn.com/806093406/files/doc_financials/2025/ar/Nike-Inc-2025_10K.pdf
|
|
输出结果:
|
|
核心依赖说明:
pdfplumber- 作用:强大的 PDF 解析库,是你代码中完美提取表格并转化为 Markdown 格式(
load_pdf_with_pdfplumber函数)的核心引擎。
- 作用:强大的 PDF 解析库,是你代码中完美提取表格并转化为 Markdown 格式(
langchain-huggingface- 作用:LangChain 官方最新分离出来的 Hugging Face 集成包。对应你代码中的
from langchain_huggingface import HuggingFaceEmbeddings,用于消除之前的 API 弃用警告。
- 作用:LangChain 官方最新分离出来的 Hugging Face 集成包。对应你代码中的
sentence-transformers- 作用:它是
HuggingFaceEmbeddings的底层依赖。负责真正从 Hugging Face Hub 下载BAAI/bge-m3模型权重,并在你的 Mac 上调用 MPS (Metal) 进行本地硬件加速计算。
- 作用:它是
faiss-cpu- 作用:Meta(Facebook)开源的本地高性能向量数据库引擎。对应你代码中的
FAISS.from_documents和FAISS.load_local,用于在本地磁盘持久化存储和极速检索向量数据。
- 作用:Meta(Facebook)开源的本地高性能向量数据库引擎。对应你代码中的
langchain生态基础包 (langchain,langchain-community,langchain-core,langchain-text-splitters)- 作用:提供基础的
Document结构、RecursiveCharacterTextSplitter(文本分块器)以及串联整个检索流程的框架化能力。
- 作用:提供基础的
常见踩坑与高频面试点
在构建语义搜索引擎和 RAG 管道的实践与面试中,核心考察点集中在对信息摄取质量的控制、高级检索算法的掌握以及底层数据库的选型上:
高频考点 1:为何必须进行文本切分?如何设定合理的 Overlap?
- 面试官提问:“大模型现在都支持几十万的长上下文了,直接把整篇文档向量化或者传给模型不行吗?为什么还要做 Chunking(切片)?”
- 满分回答:切分不仅是为了规避大模型的上下文窗口上限,核心目的是为了提升检索的信噪比(Precision/Recall)。过长的文本会被压缩进单一的稠密向量中,导致关键的局部特征被稀释,在进行余弦相似度匹配时精度会大幅下降。
设置 Chunk Overlap(通常为 10% 到 20%)是为了引入滑动窗口机制,防止自然段落或连续的上下文在物理切分边界处发生断裂,从而避免大模型因接收残缺句子而产生“断章取义”的幻觉。
高频考点 2:除了标准的余弦相似度(Similarity),还有什么检索策略?
- 面试官提问:“标准的相似度检索经常会召回几段内容高度重复的文本,浪费了模型的 Token 并且限制了信息的广度。除了标准相似度,生产中还有哪些常用的检索策略?”
- 满分回答:标准的相似度搜索确实容易导致“信息聚集(Information Redundancy)”。在工程中我们通常会引入以下进阶策略:
- MMR (Maximum Marginal Relevance, 最大边际相关性):在保证召回内容与查询意图相关的前提下,算法会主动惩罚候选文档集合内部的相似度,从而极大提升召回结果的“多样性(Diversity)”。
- 相似度阈值截断 (Similarity Score Threshold):设定一个明确的距离或分数底线,直接拦截并过滤掉相关性较弱的“长尾”低质量文档,宁可少召回也绝不给模型引入噪声。
- 混合检索 (Hybrid Search):结合传统的 BM25 词法检索(针对专有名词、编号的精准匹配)与向量稠密检索(针对语义泛化),最后通过 RRF(倒数秩融合)重排算法综合打分,这是目前业界 RAG 召回率最高的设计模式。
高频考点 3:在生产环境中,Vector Store 应该怎么选型?
- 面试官提问:“LangChain 支持几十种向量数据库,在真实的生产环境中,面对不同的业务场景你该如何进行技术选型?”
- 满分回答:向量数据库的选型本质上是针对数据规模、并发要求和现有基础设施的权衡(Trade-off):
- PoC 与本地验证阶段:首选 InMemoryVectorStore 或 FAISS。它们完全基于内存或本地文件系统,无需部署任何外部中间件,极简且查询极快,非常适合跑通 Agent 的核心逻辑。
- 中小型项目或传统架构平滑升级:推荐优先使用 PGVector(PostgreSQL 的向量扩展插件)。它可以将传统的关系型业务数据与向量特征存储在同一张表中,天然支持 ACID 事务与联合查询,极大降低了运维成本和系统复杂度。
- 十亿级以上高并发的纯 AI 检索系统:必须引入专业的分布式云原生向量数据库,如 Milvus、Qdrant 或 Pinecone。它们提供了 HNSW 等高级近似最近邻(ANN)索引算法的硬件级加速,并支持读写分离、多租户隔离与动态扩缩容,是保障大规模 RAG 系统高可用性的基石。
常见踩坑 1:VectorStore 对象直接编排导致的类型异常
- 现象与痛点:在开发执行链时,试图直接使用 chain = prompt | vector_store | llm,程序会在运行时直接抛出类型错误,提示 VectorStore 不符合 Runnable 协议。
- 核心对策:必须深刻理解 LangChain 的抽象层级。原生的 VectorStore 实例仅仅封装了底层数据库的驱动操作(如插入和相似度计算),它并未实现标准化的执行流接口。必须调用 vector_store.as_retriever() 将其转化为 VectorStoreRetriever 包装类后,系统才会赋予其 invoke、batch 等标准化方法,使其能够合规地嵌入到 Agent 或图状态机的工作流节点中。
LangSmith 监控
LangSmith 的作用
LangSmith 是专门为大模型(LLM)应用量身打造的全链路监控与调试平台,你可以把它理解为 AI 应用开发界的“X 光机”或链路追踪系统(类似传统后端的 SkyWalking/Zipkin)。
它的核心作用可以提炼为以下 4 点:
- 可视化执行链路 (Tracing):它能把一次提问的完整生命周期树状化展示。你可以清晰地看到系统哪一步在重写查询、哪一步在检索向量库、调用了什么工具(Tool),以及具体的入参和出参。
- 精准定位问题 (Debugging):这是解决“大模型胡说八道”神兵利器。当回答出错时,你可以点开链路快速溯源:到底是检索器(Retriever)搜出来的文档不对,还是大模型拿到了对的文档却产生了“幻觉”?
- 性能与成本监控 (Monitoring):精确记录每一个节点(如 Embedding 耗时、LLM 推理耗时)的毫秒级延迟,以及每一次请求消耗的 Token 数量,帮助你优化系统瓶颈并控制 API 成本。
- 提示词观测与重放 (Prompt Playground):代码里动态拼接的 Prompt 往往极其复杂。在 LangSmith 中,你可以看到发给大模型的“最终纯文本 Prompt”长什么样,甚至可以在网页上直接修改 Prompt 并重新运行测试,而无需重启本地代码。
在 RAG 应用中只要在代码开头加上这两行环境变量:
|
|
LangChain 就会自动把“大模型调用的入参出参、耗时、检索到的每一个 Chunk 的具体内容”全部可视化地呈现在网页控制台上。
获取 LangSmith API Key
- 访问 LangSmith 官网 并登录/注册。
- 在左侧导航栏找到 Settings (设置) -> API Keys。
- 点击 Create API Key 生成一个密钥(形如
lsv2_pt_...),请妥善保存。
在代码顶部注入环境变量,运行并查看“检索层”的 X 光机
打开上面的的 pdf_semantic_search.py 文件,在最顶部的 import os 之后,直接加上这三行配置:
|
|
保存后,在终端再次运行 python pdf_semantic_search.py。 运行结束后,打开 LangSmith 网页控制台,进入 Nike_Financial_RAG_Test 项目,你会看到刚才执行的几个测试问题(如 “What is Nike’s revenue in fiscal year 2025?")都生成了 Trace(追踪记录)。
在 PDF 检索场景下,LangSmith 能帮你看什么?
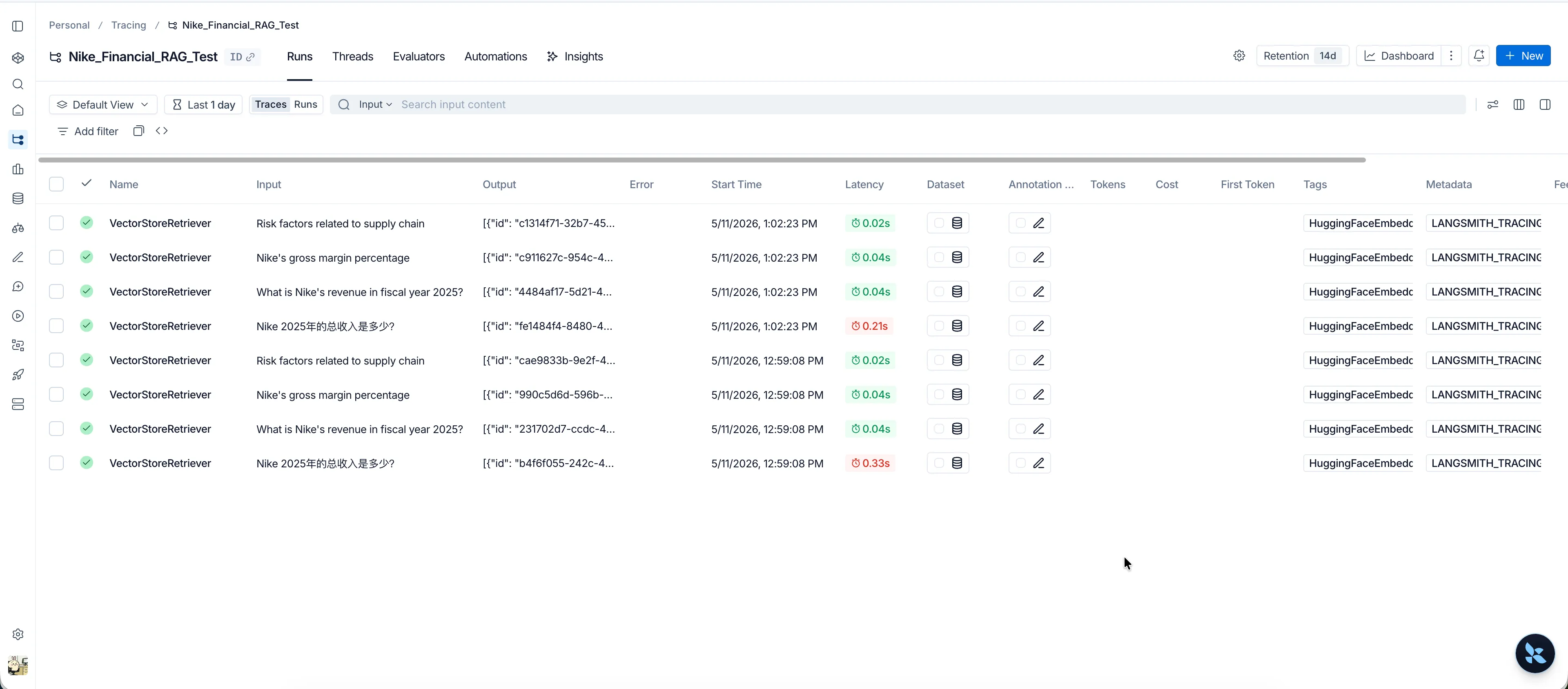
与之前带有大模型对话的 Agent 不同,你当前的脚本是一个纯粹的检索链路(Retrieval Pipeline)。点开 Trace,你会看到非常极客的底层数据:
- 精准耗时分析: 你可以清晰地看到
VectorStoreRetriever这一步花了几毫秒。以后如果你把本地 FAISS 换成云端的 Milvus 或 Pinecone,可以用这个耗时来评估网络延迟。
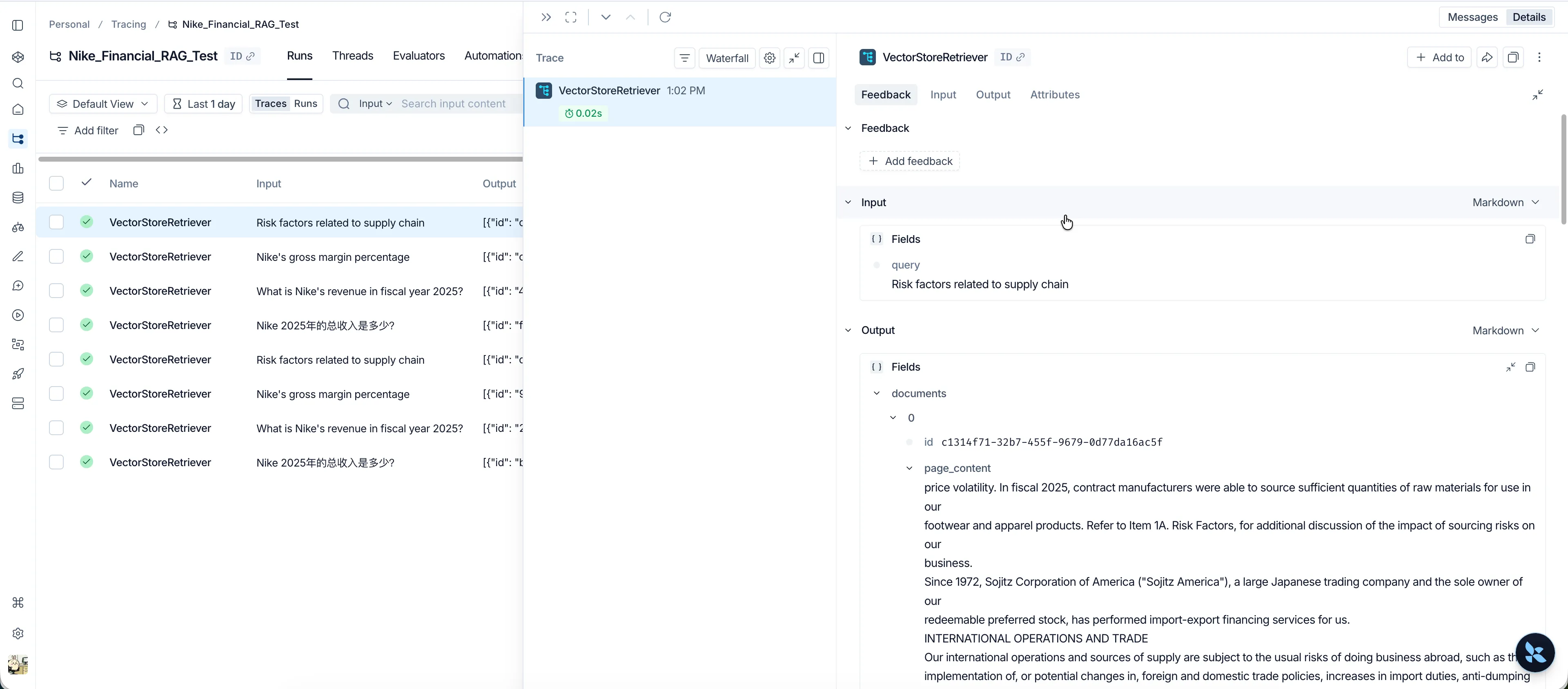
- 入参出参的“原形毕露”:
- Input: 用户的原始 Query(比如 “Risk factors related to supply chain”)。
- Output: 这是最核心的!你会直观地看到 FAISS 库返回给你的一个
List[Document]。你可以点开每一个 Document,查看它的page_content(包含你用 Markdown 格式化好的表格内容)以及metadata(来源 PDF 路径、具体的页码)。以后如果大模型答错了,你第一反应就是来这里看:“到底是数据库搜出来的数据就是个错的,还是数据给对了但大模型瞎编的?” 责任划分一目了然!
资深后端的下一步预告
当你在 LangSmith 里确认“检索出来的数据确实很准”之后,如果你接着把大模型(比如你之前用的 deepseek-chat)接入进来生成最终回答,LangSmith 的链路就会变成:
用户提问 -> Retriever 检索文档 (拿到 Context) -> 组装 Prompt -> LLM 推理 -> 最终回答
到时候,如果大模型回答错了,你只需要看一眼 LangSmith:
- 如果 Retriever 捞出来的文档就是错的 ➡️ 去优化 Embedding 或 分块策略(Chunking)。
- 如果 Retriever 捞对了,但大模型瞎编了 ➡️ 去优化 Prompt 或换个更聪明的大模型。
这就是企业级 RAG 开发中,用来解决“系统表现不好,但我不知道是谁的锅”的最佳工程手段!