Long-term memory - Docs by LangChain
一句话总结:在 LangChain 中,长效记忆(Long-term memory)是基于键值对和向量检索构建的持久化存储机制,它允许 AI Agent 突破单次会话(Thread)的生命周期限制,从而实现跨会话级别的用户个性化数据与配置的永久存储及动态召回。
常用核心概念与基础 API 讲解
长效记忆的底层实现脱离了基于 messages 列表的短期对话历史,转而使用更加结构化的文档存储机制。
存储引擎 (BaseStore)
这是提供持久化存储能力的基类。它以 JSON 文档的形式保存数据。
InMemoryStore:基于内存的存储实现,主要用于开发和本地测试。进程重启后数据丢失。PostgresStore:基于 PostgreSQL 的生产级存储实现。用于真实业务环境,提供高可用和高并发的读写支持。
数据组织结构 (Namespace & Key)
长效记忆不使用简单的平铺键值对,而是采用类似文件系统的层级结构:
- Namespace (命名空间):一个多值元组(Tuple),用于将相关数据分组归类。例如 (“users”, user_id),用于隔离不同用户的数据。多值是为了构建有深度的目录树,方便日后做细粒度的数据隔离和灵活的跨层级范围检索。注意如果只有一个值必须写成带有逗号的单元素元组。
- Key (键):命名空间下的唯一字符串标识,类似于文件名,例如 “preferences”。
核心操作 API (put & get)
存储引擎提供的标准读写方法。
store = InMemoryStore()- 写:
store.put(namespace, key, value)
- 读:
store.get(namespace, key) -> 返回 StoreValue 对象
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
|
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
# Author : nanzet
# Description : 演示长效记忆 Store 的基础 Namespace/Key 读写操作
# requirements : pip install langchain-core langgraph
from langgraph.store.memory import InMemoryStore
def demonstrate_store():
store = InMemoryStore()
# 写入数据:put(namespace, key, value)
store.put(
("users", "user_1001"),
"preferences",
{"language": "zh-CN", "theme": "dark"}
)
# 读取数据:get(namespace, key) -> 返回 StoreValue 对象
item = store.get(("users", "user_1001"), "preferences")
if item:
print(f"读取到的用户语言偏好: {item.value['language']}")
# 读取到的用户语言偏好: zh-CN
if __name__ == "__main__":
demonstrate_store()
|
工具运行时注入 (ToolRuntime & Context)
在工具(Tool)函数内部读写长效记忆,必须依赖框架在运行时的动态注入。
ToolRuntime:如果在工具参数中声明,底层会自动注入该对象,使得工具可以通过 runtime.store 获取全局存储引擎实例。Context:在调用 Agent 时,通过 context 参数传入的不可变数据(通常定义为 @dataclass 或 BaseModel,如包含当前请求的真实 user_id),在工具内部可通过 runtime.context 访问。
文档提及的其他高级 API 与机制
文档中还提到了长效记忆不仅仅是 KV 存储,还可以作为向量检索引擎使用,这是构建 RAG 高级特性的关键。
索引配置 (IndexConfig)
在使用 InMemoryStore 或 PostgresStore 初始化时,可以传入 index=IndexConfig(...)。这赋予了存储引擎将其内部的 JSON 文档进行向量化的能力。必须为其提供一个 embed(嵌入)函数和维度 dims。
内容搜索 (search)
当存储引擎配置了 IndexConfig 后,除了精确的 get,还可以使用 search 方法。它支持在特定的命名空间下,通过内容相似度(query)以及元数据过滤(filter)来检索历史记忆。
官方经典代码示例(展示内存存储的搜索能力):
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
|
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
# Author : nanzet
# Description : 官方示例:展示带有 IndexConfig 和 search 功能的长效记忆库
# requirements : pip install langchain-core langgraph
from collections.abc import Sequence
from langgraph.store.base import IndexConfig
from langgraph.store.memory import InMemoryStore
def embed(texts: Sequence[str]) -> list[list[float]]:
# 此处在生产环境应替换为真实的 LangChain 嵌入模型方法
return [[1.0, 2.0] for _ in texts]
def run_search_demo():
# 初始化带有向量索引能力的 Store
store = InMemoryStore(index=IndexConfig(embed=embed, dims=2))
user_id = "my-user"
application_context = "chitchat"
namespace = (user_id, application_context)
# 存入带有特定内容的记忆
store.put(
namespace,
"a-memory",
{
"rules": [
"User likes short, direct language",
"User only speaks English & python",
],
"my-key": "my-value",
},
)
# search 方法:按命名空间检索,支持 filter 过滤和 query 语义匹配
items = store.search(
namespace, filter={"my-key": "my-value"}, query="language preferences"
)
print(f"搜索命中数量: {len(items)}")
if __name__ == "__main__":
run_search_demo()
|
说明:
这里的 query语义匹配可以在不偏离查找目标语义的情况下自由编写,需要注意的是:模型能力越强,它对同义词、近义词、甚至跨语言(比如用中文搜这串英文记录)的理解能力就越逆天,Query 就可以写得越口语化。
工程化代码落地示例
以下是一个完全可独立运行的生产级代码骨架,展示了如何在 Agent 开发中结合 Context 校验机制,使用工具安全的读取和写入长效记忆。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
|
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
# Author : nanzet
# Description : 演示结合 Context 和 Store 的生产级长效记忆 Agent 工作流
# requirements : pip install -U langchain langgraph langchain-deepseek
from dataclasses import dataclass
from langchain.agents import create_agent
from langchain.chat_models import init_chat_model
from langchain.tools import ToolRuntime, tool
from langgraph.store.memory import InMemoryStore
from typing_extensions import TypedDict
# 定义不可变的上下文结构,用于在运行时透传业务鉴权信息
@dataclass
class Context:
user_id: str
# 定义供 LLM 使用的结构化输入 Schema
class UserInfo(TypedDict):
name: str
hobby: str
# 定义写操作工具
@tool
def save_user_info(user_info: UserInfo, runtime: ToolRuntime[Context]) -> str:
"""当用户告知他们的名字或爱好时,调用此工具保存信息。"""
assert runtime.store is not None
# 严格从 Context 中提取不可变的 user_id,确保不被大模型伪造
user_id = runtime.context.user_id
runtime.store.put(("users",), user_id, dict(user_info))
print(f"[系统日志] 成功将数据写入长效记忆: {user_info}")
return "用户信息已成功永久保存。"
# 定义读操作工具
@tool
def get_user_info(runtime: ToolRuntime[Context]) -> str:
"""在回答用户个人相关问题前,调用此工具查询用户的历史信息。"""
assert runtime.store is not None
user_id = runtime.context.user_id
user_info = runtime.store.get(("users",), user_id)
print(f"[系统日志] 正在从长效记忆检索用户 {user_id} 的信息...")
return str(user_info.value) if user_info else "当前未查询到您的历史信息。"
def main():
model = init_chat_model("deepseek-chat", model_provider="deepseek")
# 初始化全局长效记忆库
global_store = InMemoryStore()
# 创建挂载了长效记忆引擎的 Agent
agent = create_agent(
model=model,
tools=[save_user_info, get_user_info],
store=global_store,
context_schema=Context,
)
# 模拟会话 1:用户写入信息
print("--- 开启会话 1:写入长效记忆 ---")
agent.invoke(
{
"messages": [
{"role": "user", "content": "你好,我叫李四,我最喜欢的爱好是爬山。"}
]
},
# 必须显式传入 Context,注入底层的真实业务 ID
context=Context(user_id="user_9527"),
)
# 模拟会话 2:在没有任何历史 Message 记录的情况下读取信息
print("\n--- 开启独立会话 2:读取长效记忆 ---")
response = agent.invoke(
{
"messages": [
{
"role": "user",
"content": "你能根据我的爱好,推荐一项周末的活动吗?先查查我是谁。",
}
]
},
context=Context(user_id="user_9527"),
)
print("\n[AI 最终回复]:")
print(response["messages"][-1].content)
if __name__ == "__main__":
main()
|
输出结果:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
|
--- 开启会话 1:写入长效记忆 ---
[系统日志] 成功将数据写入长效记忆: {'name': '李四', 'hobby': '爬山'}
--- 开启独立会话 2:读取长效记忆 ---
[系统日志] 正在从长效记忆检索用户 user_9527 的信息...
[AI 最终回复]:
原来你是 <strong>李四</strong>,爱好是 <strong>爬山</strong>!⛰️
既然你周末喜欢爬山,我给你推荐几个很棒的活动:
---
### 🥇 推荐:**周末登山一日游**
**可选择这些地方:**
1. **深圳·梧桐山** — 深圳最高峰,风景秀丽,有多个登山口可选(适合各类难度)
2. **广州·白云山** — 轻松休闲,适合放松心情
3. **北京·香山/长城** — 如果在北京,秋季尤其适合
4. **杭州·西湖群山** — 风景优美,步道成熟
### 🎒 贴士
- 建议早上出发,避开中午暴晒
- 带好 **水、零食、防晒霜、登山杖**
- 可以约上三五好友一起,更有乐趣
---
你对哪个地方感兴趣?或者你所在的城市是哪里?我可以帮你推荐更具体的路线哦!😊
|
说明:
这两个工具函数里的 assert runtime.store is not None删除掉也能得到预期结果,写上的目的是避免可能出现的类型推导和运行时的空指针异常(NullPointerException)防范问题。测试代码也可以删掉。
在 LangChain 的底层源码中,ToolRuntime 类的 store 属性被声明为可选类型(Optional):
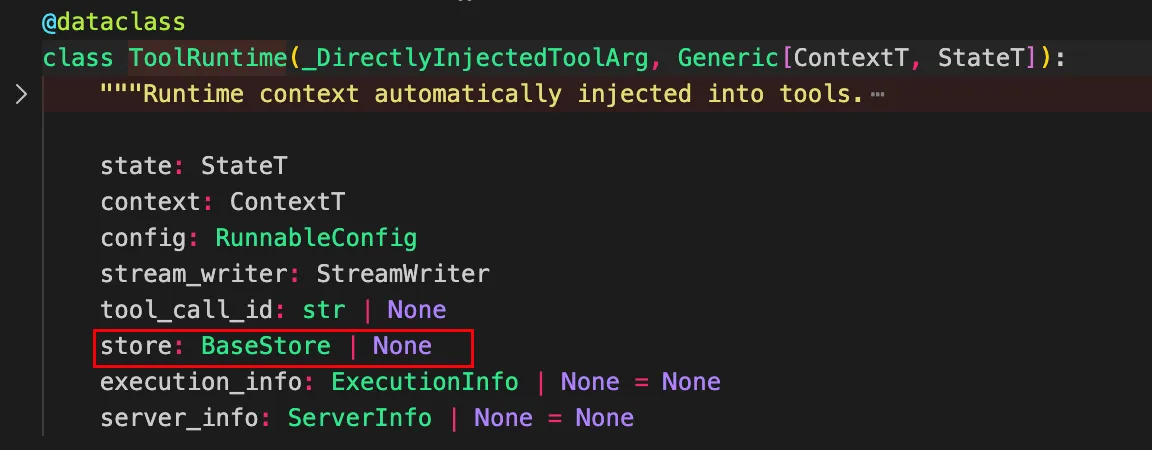
常见踩坑与高频面试点
在 AI 面试和实际架构设计中,区分记忆系统的边界与保证数据安全性是重点考察对象:
踩坑 1:混淆长短期记忆的生命周期与用途
- 高频面试点:“在设计 Agent 时,什么数据该存进短期记忆(Checkpointer),什么数据该存进长期记忆(Store)?”
- 架构思路解答:
- 短期记忆是以 messages 列表为核心的,它与 thread_id 强绑定,旨在维持单次对话的连贯性。一旦对话结束或触发截断策略,它就会丢失。
- 长期记忆(Store)则是独立于对话的,它类似于业务数据库(如用户偏好、历史总结文档),是以 namespace 隔离的全局变量。如果错误地将用户的核心偏好(如饮食禁忌)只依赖短期记忆,会导致 Agent 跨会话出现严重的“失忆症”。
踩坑 2:大模型权限越权与身份伪造
- 踩坑现场:在开发提取用户信息的 Tool 时,直接在工具签名中定义 user_id: str,要求大模型在调用工具时把用户 ID 传过来。
- 高频面试点:“在开发具有数据读写权限的 Tool 时,如何防止大模型造成的越权访问(Prompt Injection)?”
- 架构思路解答:绝对不能信任大模型传递的鉴权或身份标识参数。必须使用 ToolRuntime 的 context 机制。在后端的请求入口处(如 HTTP Header 解析后),将真实的鉴权 user_id 封装为不可变的 Context 传入
agent.invoke。在工具内部,强制读取 runtime.context.user_id 作为访问 store 的凭证。这样可以彻底在物理层面上阻断大模型篡改其他用户数据的可能。
踩坑 3:生产环境下的数据库选型失误
- 踩坑现场:项目上线后,依然使用 InMemoryStore,导致服务容器一旦重启或发生水平扩容(Scale Out)时,用户的长效记忆全量丢失。
- 架构思路解答:InMemoryStore 仅限本地单进程 Debug 使用。在真实的生产环境必须无缝替换为 PostgresStore。这是因为 PostgresStore 具备分布式环境下的数据一致性保障能力,并且原生支持并发连接,是保障多用户高频写入时服务高可用(HA)的基础规范。
核心速记卡片:Agent 长短期记忆对比
| 比较维度 |
短期记忆 (Short-term Memory) |
长期记忆 (Long-term Memory) |
| 核心作用 |
维持单次会话的对话连贯性,管理上下文窗口防 Token 溢出。 |
维持跨会话的用户级偏好与个性化配置持久化,解决 Agent “失忆症”。 |
| 隔离边界 |
绑定 thread_id(线程/会话 ID)。不同 thread_id 的记忆互不相通。 |
绑定 (namespace, key)(如用户 ID、组织 ID),全局共享,跨 Thread 读取。 |
| 底层实现机制 |
Checkpointer。
拦截 messages 列表并通过 Reducer 机制自动追加/合并状态。 |
BaseStore。
类似于后端的 KV 存储(NoSQL)或带有向量检索能力的数据库。 |
| 引入的核心对象 |
InMemorySaver (测试)
PostgresSaver (生产) |
InMemoryStore (测试)
PostgresStore (生产) |
| Agent 挂载方式 |
create_agent(..., checkpointer=saver) |
create_agent(..., store=global_store) |
| 如何读取? |
隐式读取:LLM 自动从当前 thread_id 的上下文中看到历史 messages。 |
工具读取:在 Tool 内部通过 item = runtime.store.get(namespace, key)显式捞取。 |
| 如何写入/清理? |
隐式追加:agent.invoke 自动追加。
清理:通过中间件使用 RemoveMessage 截断。 |
工具写入:在 Tool 内部通过 runtime.store.put(namespace, key, value) 显式落库。 |