Structured output - Docs by LangChain
一句话总结:结构化输出(Structured Output)机制强制大模型严格遵循预先定义的 Schema(如 Pydantic 类或 JSON 规范)进行响应,将不可控的自然语言转化为类型安全的结构化对象,从而实现 AI 推理结果与传统后端业务逻辑的无缝、安全对接。
常用核心概念与基础 API 讲解
在 LangChain 的 Agent 体系中,结构化输出主要通过 create_agent 函数的 response_format 参数进行配置。系统会捕获模型的输出,验证后将其存储在状态字典的 structured_response 键中。
response_format 接受以下几种类型的传参,以控制底层的解析策略:
type[StructuredResponseT](自动推断):直接传入目标 Schema 的类型(如 Pydantic 的 BaseModel 类)。LangChain 会根据当前所选模型的 Profile 动态检测,如果模型厂商原生支持结构化输出,则使用 ProviderStrategy;否则回退到 ToolStrategy。None:不要求结构化输出,模型按常规返回纯文本。
ProviderStrategy (原生提供商策略)
- 作用:直接利用各大模型厂商(如 OpenAI、Anthropic、Gemini)在 API 级别原生集成的结构化输出功能(如 OpenAI 的
response_format: {type: "json_schema"})。
- 特点:可靠性最高,解析速度最快。如果大模型原生支持,LangChain 会默认使用此策略。
- 参数:
schema 参数:支持 BaseModel (Pydantic)、dataclasses、TypedDict 或纯 JSON Schema 字典。strict 参数:(LangChain >= 1.2 支持) 布尔值,用于开启严格的 Schema 遵循机制。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
|
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
# Author : nanzet
# Description : 测试 ProviderStrategy 的使用,展示如何让 Agent 直接输出强类型的 Python 对象,避免了传统的字符串解析步骤。
# requirements : pip install -U langchain google-genai pydantic
from langchain.agents import create_agent
from langchain.agents.structured_output import ProviderStrategy
from langchain.chat_models import init_chat_model
from pydantic import BaseModel, Field
# 定义严格的输出结构 (DTO)
class UserProfile(BaseModel):
name: str = Field(description="用户姓名")
age: int = Field(description="用户年龄")
hobby: str = Field(description="用户爱好")
if __name__ == "__main__":
# 在项目根目录下的.env文件中配置好你的 api key,或者直接在环境变量里设置
model = init_chat_model(
"gemini-2.5-flash", model_provider="google_genai", temperature=0
)
# 强制 Agent 按 ProviderStrategy (原生能力) 输出
agent = create_agent(
model=model,
tools=[],
response_format=ProviderStrategy(UserProfile, strict=True),
)
# 触发调用
result = agent.invoke(
{
"messages": [
("user", "Nanzet Oliver 今年刚满28岁,最大的爱好是钓鱼、游泳和写代码。")
]
}
)
# 拿到的是强类型的 Python 对象, 无需再进行字符串解析
parsed_data = result["structured_response"]
print(
f"解析成功 -> 姓名: {parsed_data.name}, 年龄: {parsed_data.age}, 爱好: {parsed_data.hobby}"
)
# 解析成功 -> 姓名: Nanzet Oliver, 年龄: 28, 爱好: 钓鱼、游泳和写代码
|
- 作用:对于不原生支持结构化输出、但支持函数调用(Tool Calling)的模型,LangChain 采用此策略。其本质是将目标 Schema 伪装成一个 Tool 交给大模型调用,截获入参后作为结构化结果返回。
schema 参数:不仅支持单一种类的 Schema,还支持 Union 类型(多分支选择)。tool_message_content 参数:自定义在历史对话中留存的占位符信息(替代将复杂的 JSON 结构明文留在上下文中)。handle_errors 参数:异常处理与重试策略配置。支持传入布尔值、特定错误类型、特定字符串或自定义回调函数。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
|
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
# Author : nanzet
# Description : 演示 ToolStrategy 的使用,展示如何在没有工具的情况下,让 Agent 直接输出强类型的 Python 对象,适用于模型不支持 ProviderStrategy 的场景。
# requirements : pip install -U langchain deepseek-chat pydantic
from langchain.agents import create_agent
from langchain.agents.structured_output import ToolStrategy
from langchain.chat_models import init_chat_model
from pydantic import BaseModel, Field
# 定义严格的输出结构 (DTO)
class UserProfile(BaseModel):
name: str = Field(description="用户姓名")
age: int = Field(description="用户年龄")
hobby: str = Field(description="用户爱好")
if __name__ == "__main__":
model = init_chat_model("deepseek-chat", model_provider="deepseek", temperature=0)
# 强制 Agent 按 ToolStrategy (降级/工具策略) 输出
agent = create_agent(
model=model,
tools=[],
response_format=ToolStrategy(
schema=UserProfile,
tool_message_content="请直接输出符合 UserProfile 结构的 JSON 对象,不要添加任何多余的文本。",
handle_errors=True,
),
)
# 触发调用
result = agent.invoke(
{
"messages": [
("user", "Nanzet Oliver 今年刚满28岁,最大的爱好是钓鱼、游泳和写代码。")
]
}
)
parsed_data = result["structured_response"]
print(
f"解析成功 -> 姓名: {parsed_data.name}, 年龄: {parsed_data.age}, 爱好: {parsed_data.hobby}"
)
# 解析成功 -> 姓名: Nanzet Oliver, 年龄: 28, 爱好: 钓鱼、游泳、写代码
|
说明:
这里例如 deepseek-chat 模型不原生支持结构化输出,如果强行用ProviderStrategy会报错(如下图),这时候就必须降级用 ToolStrategy。
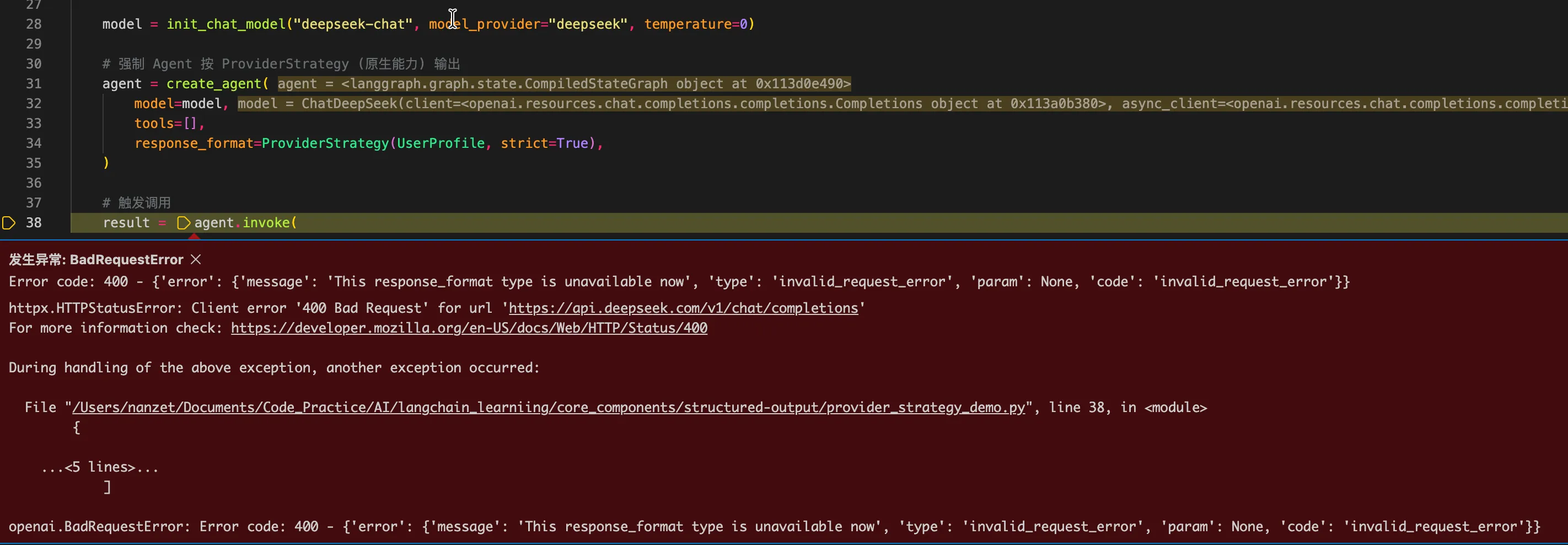
如果在开发中发现系统降级到了 ToolStrategy (工具调用策略),就必须在架构上拉响警报,并做好以下防御性设计:
- 必须开启重试机制:原生结构化输出几乎不会出错,但 Tool Calling 会!你必须配置我们之前代码中的
handle_errors=True 或自定义的 Retry 拦截器。因为模型本质上是在“裸写 JSON 字符串”,它随时可能少写一个逗号或者把 Integer 传成 String。
- Schema 尽量扁平化:如果确定底层走的是 ToolStrategy,定义 Pydantic Schema 时要尽量避免嵌套超过 3 层以上的复杂字典或数组。对于缺乏原生强制约束的开源模型,Schema 嵌套越深,它产生幻觉和格式破坏的概率呈指数级上升。
文档提到的其他扩展 API 与类名
为了支撑结构化输出的灵活性和高可用性,文档在核心策略之外,还引入了以下配套的进阶机制与内置类:
结构化异常类 (配合 handle_errors 使用)
当底层降级使用 ToolStrategy (工具调用策略) 时,由于大模型本质上是在拼接 JSON 字符串,极易发生格式崩溃或幻觉。此时,框架会抛出以下特定的内置异常,供后端进行精确捕获和重试路由:
- StructuredOutputValidationError (结构验证错误)
当模型返回的 JSON 字段无法通过 Pydantic 模型的严格校验(例如:字段缺失,或要求 1-5 的整数但模型返回了 10)时,底层会抛出此异常。
- MultipleStructuredOutputsError (多重输出错误)
当模型产生幻觉,违反了“单次仅输出一个结构化对象”的设定,错误地在一次并发响应中下发了多个工具调用指令时,触发此异常。
Schema 动态路由机制:Union (多类型联合)
这是针对复杂业务场景的高级类型分发(Type Dispatching)机制。
- 结合 Python 的 typing.Union,我们可以在定义 ToolStrategy 的 schema 参数时,一次性提供多个完全不同的对象模型(例如 Union[ProductReview, CustomerComplaint])。
- 工程价值:将“意图识别”和“结构化抽取”合二为一。大模型会先根据用户的提示词上下文自主判断这属于“产品评价”还是“客户投诉”,然后动态选择最匹配的那个 Schema 结构进行 JSON 输出,极大地简化了后端的路由判断代码。
示例代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
|
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
# Author : nanzet
# Description : 演示 ToolStrategy 的自纠错机制:通过 Pydantic 触发 StructuredOutputValidationError 并让大模型自动修复
# requirements : pip install -U langchain langchain-deepseek pydantic
from langchain.agents import create_agent
from langchain.agents.structured_output import (
StructuredOutputValidationError,
ToolStrategy,
)
from langchain.chat_models import init_chat_model
from pydantic import BaseModel, Field
class Rating(BaseModel):
score: int = Field(description="必须是 1 到 5 之间的整数", ge=1, le=5)
def main():
model = init_chat_model("deepseek-chat", model_provider="deepseek", temperature=0)
# 开启精准的异常捕获与自我修复循环
agent = create_agent(
model=model,
tools=[],
response_format=ToolStrategy(
schema=Rating,
# 【核心考点】:只拦截因 Pydantic 校验失败引发的结构化错误,打回给模型重试
handle_errors=StructuredOutputValidationError,
),
)
print("--- 开始测试:故意诱导模型犯错 ---")
# 故意给出 10 分,诱导大模型打破 Pydantic ge=1, le=5 的约束
result = agent.invoke(
{"messages": [("user", "这个商品太棒了,我要给它打 10 分!")]}
)
print("\n🕵️ [内部对话流转日志 - 揭秘自愈过程]:")
for msg in result["messages"]:
if msg.type == "human":
print(f"👤 用户: {msg.content}")
elif msg.type == "ai" and msg.tool_calls:
print(f"🤖 AI 尝试输出: {msg.tool_calls[0]['args']}")
elif msg.type == "tool":
print(f"❌ 拦截器反馈 (ToolMessage): \n{msg.content}")
print("\n✅ [最终纠正后的结果]:")
print(repr(result.get("structured_response")))
if __name__ == "__main__":
main()
|
输出结果:
1
2
3
4
5
6
7
8
9
10
|
--- 开始测试:故意诱导模型犯错 ---
🕵️ [内部对话流转日志 - 揭秘自愈过程]:
👤 用户: 这个商品太棒了,我要给它打 10 分!
🤖 AI 尝试输出: {'score': 5}
❌ 拦截器反馈 (ToolMessage):
Returning structured response: score=5
✅ [最终纠正后的结果]:
Rating(score=5)
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
|
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
# Author : nanzet
# Description : 演示 MultipleStructuredOutputsError 触发与自纠错机制
# requirements : pip install -U langchain langchain-deepseek pydantic
from typing import Union
from langchain.agents import create_agent
from langchain.agents.structured_output import (
MultipleStructuredOutputsError,
ToolStrategy,
)
from langchain.chat_models import init_chat_model
from pydantic import BaseModel, Field
class ContactInfo(BaseModel):
"""人员联系信息"""
name: str = Field(description="人员姓名")
email: str = Field(description="电子邮件地址")
class EventDetails(BaseModel):
"""事件详细信息"""
event_name: str = Field(description="事件名称")
date: str = Field(description="事件日期")
def main():
model = init_chat_model("deepseek-chat", model_provider="deepseek", temperature=0)
# 开启精准的并发输出异常捕获与自我修复循环
agent = create_agent(
model=model,
tools=[],
response_format=ToolStrategy(
# 允许模型从两个 Schema 中二选一
schema=Union[ContactInfo, EventDetails],
# 专门捕获“多重输出”错误,打回给模型重试
handle_errors=MultipleStructuredOutputsError,
),
)
print("--- 开始测试:故意诱导模型并发输出多个结果 ---")
# 故意给一段包含两种信息的文本,并暗示提取全部,诱发大模型同时调用两个 Schema
prompt = (
"提取以下信息:张三 (zhangsan@email.com) 正在组织 3月15日 的 AI 技术大会。"
"请把你能找到的人员信息和会议信息都提取出来。"
)
result = agent.invoke({"messages": [("user", prompt)]})
print("\n[内部对话流转日志 - 揭秘并发拦截与自愈过程]:")
for msg in result["messages"]:
if msg.type == "human":
print(f"👤 用户: {msg.content}")
elif msg.type == "ai" and msg.tool_calls:
print(f"🤖 AI 尝试并发输出 {len(msg.tool_calls)} 个结果:")
for tc in msg.tool_calls:
print(f" -> Schema选择: {tc['name']}, 提取数据: {tc['args']}")
elif msg.type == "tool":
print(f"❌ 拦截器反馈 (ToolMessage): \n{msg.content}")
print("\n✅ [最终纠正后的结果]:")
print(repr(result.get("structured_response")))
if __name__ == "__main__":
main()
|
输出结果:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
--- 开始测试:故意诱导模型并发输出多个结果 ---
[内部对话流转日志 - 揭秘并发拦截与自愈过程]:
👤 用户: 提取以下信息:张三 (zhangsan@email.com) 正在组织 3月15日 的 AI 技术大会。请把你能找到的人员信息和会议信息都提取出来。
🤖 AI 尝试并发输出 2 个结果:
-> Schema选择: ContactInfo, 提取数据: {'name': '张三', 'email': 'zhangsan@email.com'}
-> Schema选择: EventDetails, 提取数据: {'event_name': 'AI 技术大会', 'date': '3月15日'}
❌ 拦截器反馈 (ToolMessage):
Error: Model incorrectly returned multiple structured responses (ContactInfo, EventDetails) when only one is expected.
Please fix your mistakes.
❌ 拦截器反馈 (ToolMessage):
Error: Model incorrectly returned multiple structured responses (ContactInfo, EventDetails) when only one is expected.
Please fix your mistakes.
🤖 AI 尝试并发输出 1 个结果:
-> Schema选择: ContactInfo, 提取数据: {'name': '张三', 'email': 'zhangsan@email.com'}
❌ 拦截器反馈 (ToolMessage):
Returning structured response: name='张三' email='zhangsan@email.com'
✅ [最终纠正后的结果]:
ContactInfo(name='张三', email='zhangsan@email.com')
|
说明:
- 大模型的并发陷阱:在第一轮中,DeepSeek 模型极其出色地完成了任务,它准确识别了两个实体,并发起了两次并行的 Tool Call。但这就违背了系统层面的“单例 DTO 返回”契约。
- 底层引擎的安全拦截:LangChain 的执行引擎(ToolNode)在收集结果时,发现本该出现 1 个的结构化对象出现了 2 个,于是立即阻断业务,抛出 MultipleStructuredOutputsError。
- 精准打回与模型自愈:框架自动生成了带有官方英文警告(Model incorrectly returned multiple structured responses…)的两个 ToolMessage 发回给大模型。大模型在第二轮思考时,意识到只能“二选一”,于是忍痛割爱放弃了事件信息,仅输出了 ContactInfo 对象,保证了后端程序的顺利反序列化,彻底避免了服务宕机。
工程化代码示例
以下是提取自官方文档并经过完善的生产级经典代码示例,包含了自动策略选择、Union 类型处理以及自定义重试回调函数的完整逻辑。
示例 1:基于 ProviderStrategy 的自动路由与提取
展示直接传递 Pydantic Schema 让框架自动路由原生策略的经典用法。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
|
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
# Author : nanzet
# Description : 演示使用 create_agent 自动选择 ProviderStrategy 提取结构化联系人信息
# requirements : pip install -U langchain langchain-deepseek pydantic
from langchain.agents import create_agent
from langchain.chat_models import init_chat_model
from pydantic import BaseModel, Field
class ContactInfo(BaseModel):
"""联系人信息数据结构。"""
name: str = Field(description="人员的真实姓名")
email: str = Field(description="人员的电子邮件地址")
phone: str = Field(description="人员的联系电话号码")
def main():
# 初始化 DeepSeek 模型
model = init_chat_model("deepseek-chat", model_provider="deepseek", temperature=0)
# 直接传入 Pydantic 类,LangChain 将自动探测模型能力并选择最优提取策略 (ProviderStrategy)
agent = create_agent(model=model, tools=[], response_format=ContactInfo)
print("--- 正在请求大模型提取非结构化文本 ---")
# 传入一段非结构化的纯中文乱码/口语化文本
prompt = "麻烦帮我把这个名片上的信息录入一下:客户名字叫王建国,他的邮箱是 wangjg_2026@company.cn,有事可以打他手机 138-1234-5678。"
result = agent.invoke({"messages": [{"role": "user", "content": prompt}]})
print("\n✅ [最终的结构化响应数据对象]:")
print(repr(result["structured_response"]))
if __name__ == "__main__":
main()
|
输出结果:
1
2
3
4
|
--- 正在请求大模型提取非结构化文本 ---
✅ [最终的结构化响应数据对象]:
ContactInfo(name='王建国', email='wangjg_2026@company.cn', phone='138-1234-5678')
|
展示如何应对复杂提取场景及控制模型的自我修复逻辑。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
|
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
# Author : nanzet
# Description : 演示使用 ToolStrategy 处理 Union 类型和自定义异常反馈循环
# requirements : pip install -U langchain langchain-deepseek pydantic
from typing import Union
from langchain.agents import create_agent
from langchain.agents.structured_output import (
MultipleStructuredOutputsError,
StructuredOutputValidationError,
ToolStrategy,
)
from langchain.chat_models import init_chat_model
from pydantic import BaseModel, Field
class ContactInfo(BaseModel):
"""人员联系方式"""
name: str = Field(description="人员姓名")
email: str = Field(description="电子邮件地址")
class EventDetails(BaseModel):
"""活动详细信息"""
event_name: str = Field(description="活动或会议的名称")
date: str = Field(description="举办日期")
def custom_error_handler(error: Exception) -> str:
"""自定义异常处理回调:将不同的内部报错转化为易于模型理解的【中文提示词】,促使其重新生成。"""
if isinstance(error, StructuredOutputValidationError):
return "警告:您提取的数据格式不符合要求,或者缺少了必填字段。请仔细核对并重新提取一次。"
elif isinstance(error, MultipleStructuredOutputsError):
return "警告:您同时输出了多个结构化结果!业务要求您必须只能选择其中【最相关的一个】进行输出。请做出抉择并重试。"
else:
return f"发生未知错误: {str(error)}"
def main():
model = init_chat_model("deepseek-chat", model_provider="deepseek", temperature=0)
agent = create_agent(
model=model,
tools=[],
response_format=ToolStrategy(
# 允许大模型结合上下文,在联系人和会议中自动二选一
schema=Union[ContactInfo, EventDetails],
# 挂载自定义的异常翻译器
handle_errors=custom_error_handler,
),
)
print("--- 开启测试:联合类型解析 ---")
prompt = "请帮我提取这段行程信息:赵明 (zhao_m@email.com) 正在筹备将于 5月20日 举办的 2026年度开发者大会。"
result = agent.invoke({"messages": [{"role": "user", "content": prompt}]})
print("\n🕵️ [内部对话流转日志]:")
for msg in result["messages"]:
# 打印框架反馈给模型的自定义错误消息或工具执行消息
if type(msg).__name__ == "ToolMessage":
print(f"🔧 工具反馈 (ToolMessage): {msg.content}")
elif msg.type == "ai" and msg.tool_calls:
print(f"🤖 AI 尝试提取实体: {msg.tool_calls}")
print("\n✅ [最终提取的结构化结果]:")
print(repr(result.get("structured_response")))
if __name__ == "__main__":
main()
|
输出结果:
1
2
3
4
5
6
7
8
9
10
11
|
--- 开启测试:联合类型解析 ---
🕵️ [内部对话流转日志]:
🤖 AI 尝试提取实体: [{'name': 'ContactInfo', 'args': {'name': '赵明', 'email': 'zhao_m@email.com'}, 'id': 'call_00_sMtyQJvIZ9Zl3onwfbn73409', 'type': 'tool_call'}, {'name': 'EventDetails', 'args': {'event_name': '2026年度开发者大会', 'date': '5月20日'}, 'id': 'call_01_E8jAmTGHwDSN0nb2QIrA3013', 'type': 'tool_call'}]
🔧 工具反馈 (ToolMessage): 警告:您同时输出了多个结构化结果!业务要求您必须只能选择其中【最相关的一个】进行输出。请做出抉择并重试。
🔧 工具反馈 (ToolMessage): 警告:您同时输出了多个结构化结果!业务要求您必须只能选择其中【最相关的一个】进行输出。请做出抉择并重试。
🤖 AI 尝试提取实体: [{'name': 'EventDetails', 'args': {'event_name': '2026年度开发者大会', 'date': '5月20日'}, 'id': 'call_00_lhXkSpdSOuWjNVVcfqMm6184', 'type': 'tool_call'}]
🔧 工具反馈 (ToolMessage): Returning structured response: event_name='2026年度开发者大会' date='5月20日'
✅ [最终提取的结构化结果]:
EventDetails(event_name='2026年度开发者大会', date='5月20日')
|
常见踩坑与高频面试点(后端进阶版)
在 AI 开发的面试和实际业务落地中,结构化输出是非常考验研发系统健壮性设计的核心话题。掌握以下四点,能极大展现你的工程深度:
- 高频面试点:“在做信息提取抽取 Agent 时,原生结构化 API 和基于 Tool Calling 的提取有什么底层区别?”
- 满分回答:
- ProviderStrategy (原生支持):调用的是厂商提供的原生 JSON Schema 强制约束模式。其本质是受限解码(Constrained Decoding),解析和约束是在模型推理的物理引擎层完成的,在 Token 生成阶段就从概率层面直接阻断了非法字符的产生。速度更快、准度极高、Token 开销更小。
- ToolStrategy (降级方案):是一种妥协方案。它实际上是在 Prompt 里塞入了一个虚拟的函数定义,依赖模型自身的“指令遵循能力”去生成一段包含 JSON 参数的文本,再由 LangChain 拦截并反序列化。由于本质还是在做自然语言生成,存在拼写错误或漏传参数的风险,必须配合重试机制使用。
架构解耦:Schema 过于复杂导致的幻觉崩塌
- 踩坑现场:为了省事,直接把一个包含十几层嵌套、几十个字段的庞大 Pydantic BaseModel 塞给 response_format。结果大模型频繁报 ValidationError,甚至因为找不准上下文而出现严重的幻觉。
- 核心对策:大模型不是全能的 AST 解析器,嵌套越深,大模型的注意力(Attention)越容易分散。最佳实践是引入微服务的拆分解耦思维:先用一个主控 Agent 提取顶层意图,再将具体的复杂字段路由给下游更垂直的子 Agent 去提取。Schema 定义必须保持“扁平化”,且 description 字段的描述务必清晰无歧义。
高可用性设计:自纠错(Self-Correction)引发的“重试死循环”
- 踩坑现场:配置了 handle_errors=True 后,大模型遇到 ValidationError 开始自我修复。但由于给出的 Schema 规则与用户的 Prompt 存在不可调和的冲突,模型连续修了 10 次还是错的,导致接口长时间阻塞,触发无意义的巨额计费。
- 核心对策:绝不能放任框架无限重试。在生产环境中必须做两层底线防守:
- 底层熔断:在构建 LangGraph 的配置中设置严格的 recursion_limit(递归深度限制,比如最多重试 3 次)。
- 业务降级:在设计自定义的错误处理函数(Callable handler)时,对于某些致命的解析错误,不要一味反馈给模型重试,而是捕获特定的异常(如 MultipleStructuredOutputsError)并直接向外抛出(Raise),在后端接入人工客服(Human-in-the-loop)接管或返回默认的兜底配置。
成本与性能控制:上下文的 Token 膨胀陷阱
- 踩坑现场:使用 ToolStrategy 提取了上千字的 JSON 结构化数据,由于多轮对话的特性,这些巨大的 JSON 结果被原封不动地保存在了对话历史的 ToolMessage 中。后续用户继续提问时,大模型的响应速度急剧下降且计费暴增。
- 核心对策:必须熟练配置 ToolStrategy 中的 tool_message_content 属性。将其设置为类似于“目标数据结构提取已完成并入库”的简短提示语。这样,长篇大论的 JSON 将被拦截并转换为对象返回给后端业务,而留在上下文历史记录中的只有这句简短的反馈,从而大幅缩减网络 I/O 延迟和 Token 冗余。